AI-Assisted Bioinformatics
Machine learning-enabled workflows for biomarker discovery, variant prioritization, and predictive genomics.
AI-Powered Long-Read Sequencing Analysis for Genome Assembly, Structural Variants & Transcriptomics
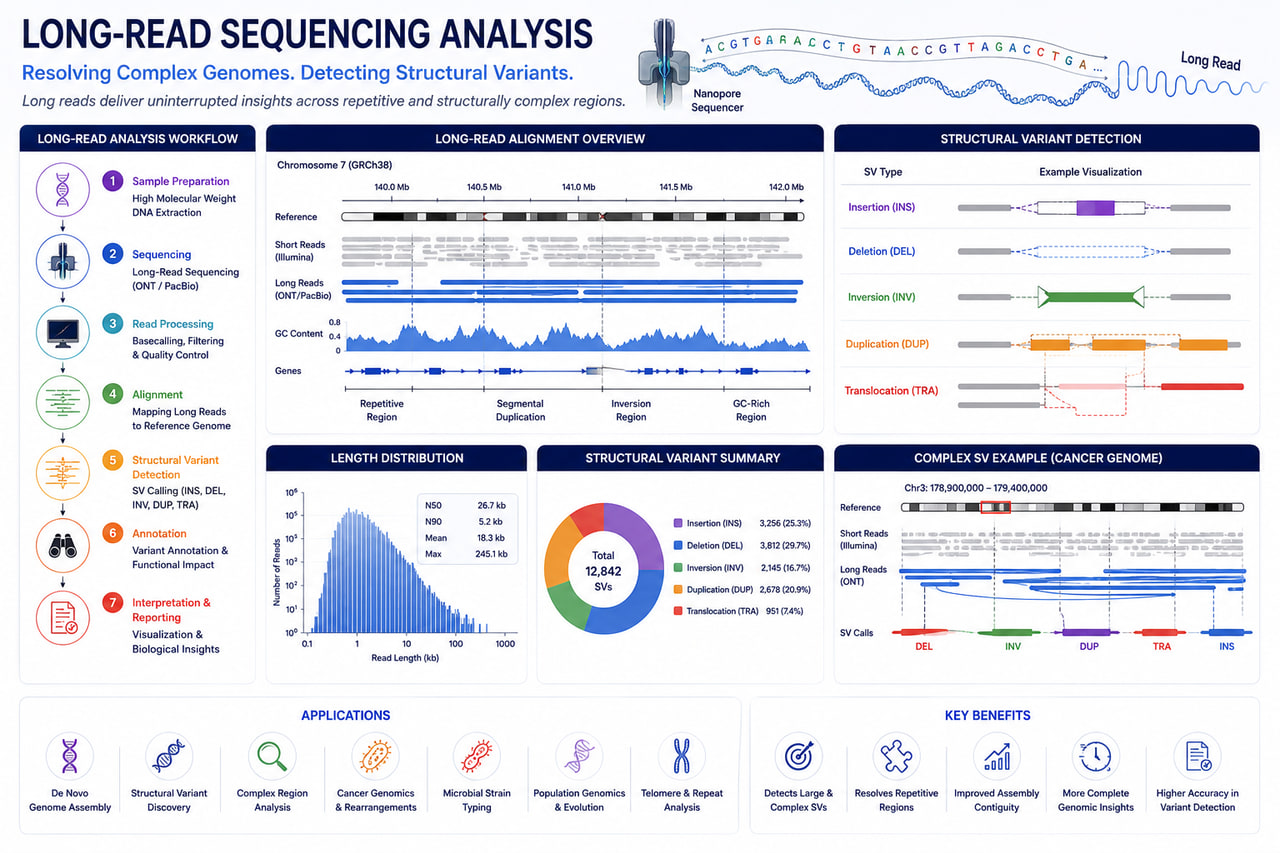
RASA Life Science Informatics provides advanced Long-Read Sequencing analysis services to help researchers unlock complex genomic and transcriptomic insights that are difficult to resolve using conventional short-read sequencing technologies. Our bioinformatics workflows support Oxford Nanopore Technologies (ONT), PacBio HiFi, Iso-Seq, and hybrid sequencing approaches for comprehensive genome characterization and transcriptome analysis.
Long-read sequencing enables accurate detection of structural variants, repeat regions, complex genomic rearrangements, alternative splicing events, isoform diversity, and de novo genome assemblies. We help pharmaceutical companies, biotechnology organizations, hospitals, research institutes, CROs, and academic laboratories transform long-read sequencing data into actionable biological insights through scalable, cloud-ready, and reproducible bioinformatics pipelines.
Our services support applications in human genomics, cancer genomics, rare disease research, microbial genomics, plant genomics, precision medicine, and drug discovery.
Comprehensive analysis of nanopore sequencing data for genomic and transcriptomic applications.
High-accuracy long-read analysis for genome characterization and variant discovery.
Full-length transcript sequencing for comprehensive transcriptome characterization.
Detection and characterization of large-scale genomic variations.
Reference-free genome reconstruction using long-read sequencing data.
Rare disease research, precision medicine, and clinical genomics applications.
Structural variant discovery and tumor genome characterization.
Full-length transcript sequencing and isoform analysis.
Genome assembly, pathogen characterization, and comparative genomics.
Complex genome assembly and crop genomics research.
Target discovery, transcript characterization, and biomarker identification.
Detection of large genomic rearrangements not identifiable with short-read sequencing.
High-quality de novo and hybrid genome assemblies.
Comprehensive characterization of transcript isoforms and alternative splicing events.
Identification of clinically relevant structural variants and complex genomic alterations.
Detection of novel genomic and transcriptomic biomarkers.
Machine learning-enabled workflows for biomarker discovery, variant prioritization, and predictive genomics.
Support for Illumina, Oxford Nanopore, PacBio HiFi, and 10x Genomics platforms.
From raw sequencing data to biological interpretation and publication-ready reports.
Deployable on AWS, Google Cloud, HPC clusters, and secure on-premise environments.
Built using Nextflow, Snakemake, Docker, and Singularity for enterprise-grade bioinformatics operations.
Get in touch with our team in Pune, India to discuss sample sizes, platform details, and custom bioinformatics pipeline configurations for your research program.
Start a Project